In this article, we’ll learn about Pandas read CSV file. We’ll first understand what CSV files are, then we’ll learn how to properly read them using the Python pandas read csv function. Also, we’ll explore the parameters of read csv function to customize the visualization of data with the help of practical code examples.
Pandas Read CSV File
It specifies visualizing the data of a CSV file in a more readable format with the help of the read csv function that comes from the Pandas library.
What is CSV File?
It is a file that consists of comma-separated values(CSV). An example of a CSV file format is file.csv. It can be used to store tabular data. The benefits of using CSV file includes that its easily understandable, universally used, and easy and quick creation
Use of CSV File
In the projects of Data Science, we import data that is mostly in a CSV format. This data is read and write in a way that meets the project requirements.
Datasets used in the Examples
Here are the links to the datasets that are used in the below examples.
Student Results DataSet
IT Companies DataSet
9 Examples of Pandas Read CSV File
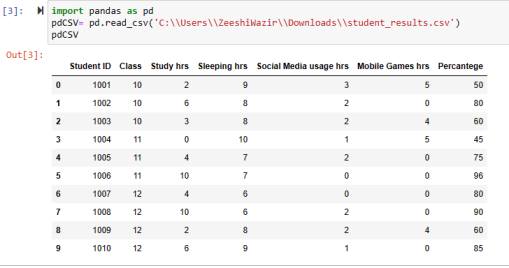
Example 1: Creating Dataframe using CSV File
import pandas as pd
pdCSV= pd.read_csv('C:\\Users\\ZeeshiWazir\\Downloads\\student_results.csv')
pdCSV
Output
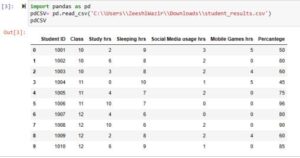
In this code, we called the read_csv function of the panda’s library and passed it the path where our CSV file is placed. Make sure to use the double slash(\\) when specifying the path in case some errors occur. Also, make sure to specify the correct path and also use the file name with the extension(.csv in this case).
In the above image, we can see that the comma-separated values data is now visualized in a very professional manner. It now has rows and columns and this 2D data structure is called a Dataframe.
Example 2: Creating Series using CSV File
srs= pd.read_csv('C:\\Users\\ZeeshiWazir\\Downloads\\it_companies.csv')
srs
Output
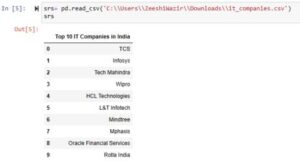
We used another CSV file and passing it to the pandas read csv function gives us a 1D data structure i.e. Pandas Series.
Example 3: Fetch Current Directory where File is Stored
When passing a file to read csv function then this file gets stored in the current working directory. And by default, it gets stored in your User’s account. In order to see where it’s stored, see below code:
import os print(os.getcwd())
Output
C:\Users\[Your Account]\Python Pandas B_to_A
We need to import the ‘os‘ module and call its getcwd() function to fetch the current directory where file is stored.
Example 4: Setting First Row to be Header(parameter ‘header’)
dfVal= pd.read_csv('C:\\Users\\ZeeshiWazir\\Downloads\\student_results.csv', header=0)
dfVal
Output
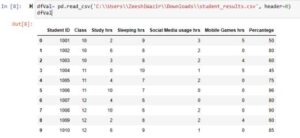
By using this parameter, we can set which row should be used as header. Giving it None will generate a header starting from 0. See below:
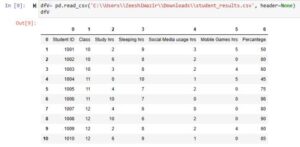
Example 5: index_col to specify which column to use as index
index_col='Student ID'
Output
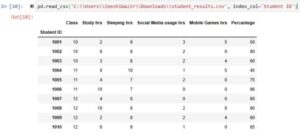
We’ll set it to ‘Student ID’. You can use other column names as well. In this image, you can see that index is now taken from the column ‘Student ID’.
Example 6: Read specific columns using parameter ‘usecols’
usecols=['Sleeping hrs','Mobile Games hrs']
Output
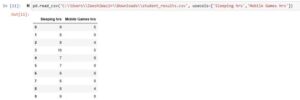
In this image, we can see that only the specified columns are taken.
Example 7: parameter ‘dtype’ to set the datatype of column items
dtype={'Study hrs':float,'Percantege':float}
Output

In this example, we changed the datatype of the 2 specific columns from integer to float and the result can be shown in the image.
Example 8: Skip some beginning rows using parameter ‘skiprows’
skiprows=7
Output
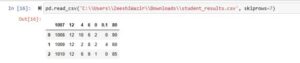
We skipped the first 7 rows with the help of parameter ‘skiprows’.
Example 9: Set some values to be NaN using parameter ‘na_values’
na_values=[0,1]
Output
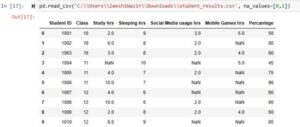
In our data set, we set the value 0 and 1 to be taken as NaN and in the output we can see that the specified values(0 and 1 in this case) are replaced with NaN. You can try it with other values as well. This parameter(na_values) allows us to give it a list of values that we want to be taken as NaN.
Here you can find more information about the other parameters of read_csv() function.
Conclusion
In conclusion, we learned about the Pandas Read CSV file. We discussed the read_csv function in detail that how we can read a csv file and modify its visualization using the parameters of this function.
Do visit our other articles for more detailed information on Python data science. Also, stay tuned for more exciting articles on write CSV file and many more. Thank you for reading this one.